初學者也能快速上手的Python爬蟲(2) - 安裝兩個重要的Package

上一篇:初學者也能快速上手的Python爬蟲(1) - Anaconda安裝與Jupyter Notebook使用
今天會需要用到兩個package:
- Requests
- BeautifulSoup
Requests

如果想要使用 Python 來下載網頁上的資料,最基本的作法就是以 requests 模組建立適當的 HTTP 請求,透過 HTTP 請求從網頁伺服器下載指定的資料。
Requests 是以 PEP 20 的箴言為中心開發的
- Beautiful is better than ugly.(美麗優於醜陋)
- Explicit is better than implicit.(直白優於含蓄)
- Simple is better than complex.(簡單優於復雜)
- Complex is better than complicated.(複雜優於繁瑣)
- Readability counts.(可讀性很重要)
功能特性
Requests 完全滿足今日 web 的需求。
- Keep-Alive & 連接池
- 國際化域名和 URL
- 帶持久 Cookie 的會話
- 瀏覽器式的 SSL 認證
- 自動內容解碼
- 基本/摘要式的身份認證
- 優雅的 key/value Cookie
- 自動解壓
- Unicode 響應體
- HTTP(S) 代理支持
- 文件分塊上傳
- 流下載
- 連接超時
- 分塊請求
- 支持 .netrc
安裝方法
安裝及使用教程官方網站也有詳細的說明,這邊就簡單提一下。
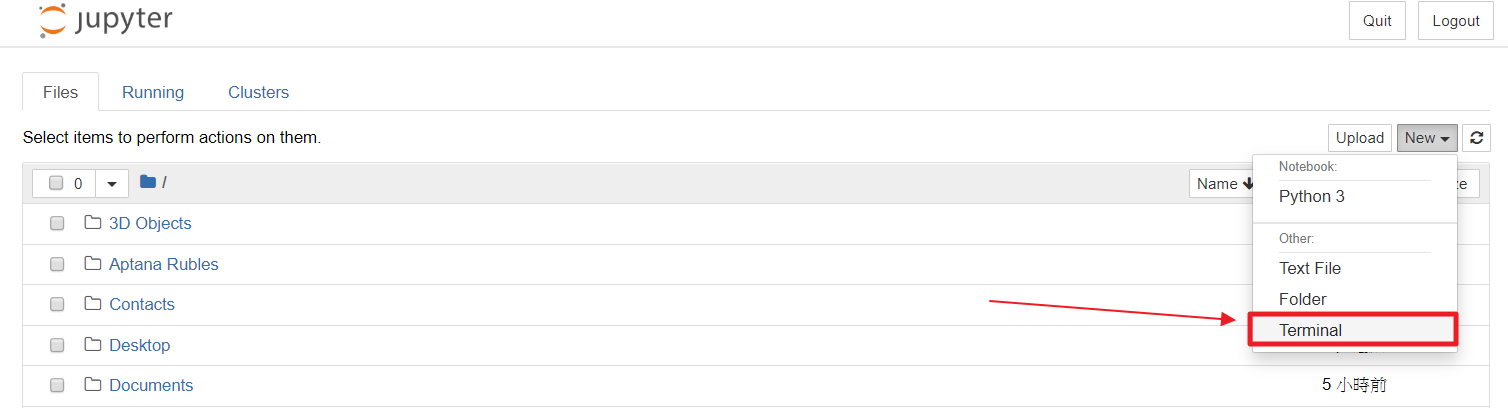
你只需要打開終端運行指令即可安裝,例如在Jupyter Notebook的首頁找到New - Terminal打開終端,透過在終端輸入指令來安裝requests:
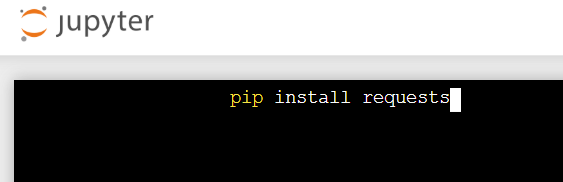
pip install requests
引入模組方法
# 引入 Requests 模組
import requests
Beautiful Soup

Beautiful Soup 是一個可以從HTML或XML文件中提取數據的Python庫。
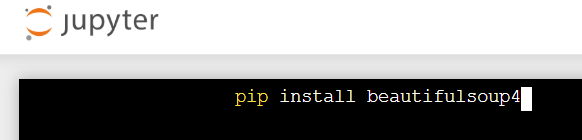
安裝方法
同requests的安裝方法。
引入模組方法
# 引入 Beautiful Soup 模組
from bs4 import BeautifulSoup
更多使用方法可以參閱官方文檔