初學者也能快速上手的Python爬蟲(3) - 抓取Yahoo奇摩新聞首頁標題與連結

本篇文章適用於對python以及html語法略懂皮毛的初學者,若什麼都不瞭解建議邊學邊google,畢竟現代科技非常發達嘛。
上一篇:初學者也能快速上手的Python爬蟲(2) - 安裝兩個重要的Package
解析網頁內容及標籤
我們今天學習的目標是抓取Yahoo奇摩首頁的新聞標題。
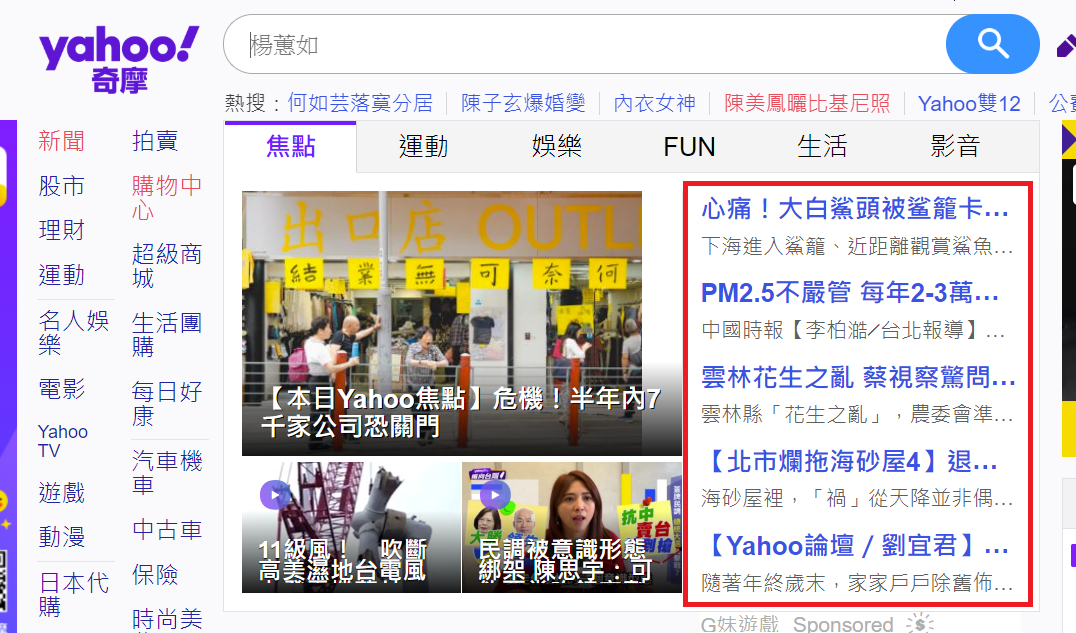
並且我希望呈現下方的形式:
新聞標題:xxxxxxx
新聞地址:http://........
首先,你可以透過Ctrl+Shift+I或者F12打開"開發人員工具",並且點擊選取工具指向想要抓取的資料位置,就會自動跳到該資料的程式碼位置。

注:建議使用Google Chrome或者Fire Fox瀏覽器。
大致看一下每個標題之間標籤的共通點,例如這篇新聞標題是以連結標籤包裹住的,class名稱為D-b Abu-C-b Fw-b Mb-6 Ell Fz-m Cur-p story-title,若是你仔細觀察,可以發現每一個新聞標題超連結的class都是一樣的,我們可以只使用其中的一部分story-title或者全部使用皆可。
<a href="https://bit.ly/2rDxQ5R" class="D-b Abu-C-b Fw-b Mb-6 Ell Fz-m Cur-p
story-title"data-ylk="rspns:nav;t1:a3;t2:td;t3:nav;sec:td-fea;elm:hdln;elmt:ct;itc:0;
cpos:3;pkgt:1;ccode:p_zh_hant_tw_lm_or1;aid:id-6232;
g:da398d27-7f67-354b-a8da-a233efb81343;cat:t5;subsec:t5;ct:1;ad:0;slk:賈靜雯也掃貨?櫃姐卻
曝1憾;" data-rapid_p="74" data-v9y="1" id="yui_3_12_0_3_1576066112353_2420"><span
class="Va-tt" id="yui_3_12_0_3_1576066112353_2419">賈靜雯也掃貨?櫃姐卻曝1憾</span></a>
抓取需要的資料
- 在最開始需要先import requests和BeautifulSoup4。
import requests
from bs4 import BeautifulSoup

- 接著使用 GET 方式下載普通網頁,並將網頁內容儲存在res變數中,接著輸入
print(res.status_code)來確認伺服器回應的狀態碼,若顯示200代表OK沒問題。
res = requests.get("https://tw.yahoo.com/")
# 確認伺服器回應的狀態碼,可不寫
print(res.status_code)
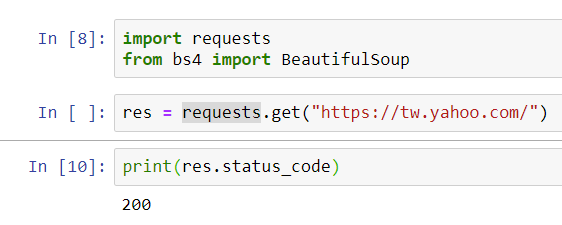
注:HTTP狀態碼
- 輸入
print(res.text)可以印出網頁的原始碼,你可以在這研究一下標題們的標籤之間的共同點。
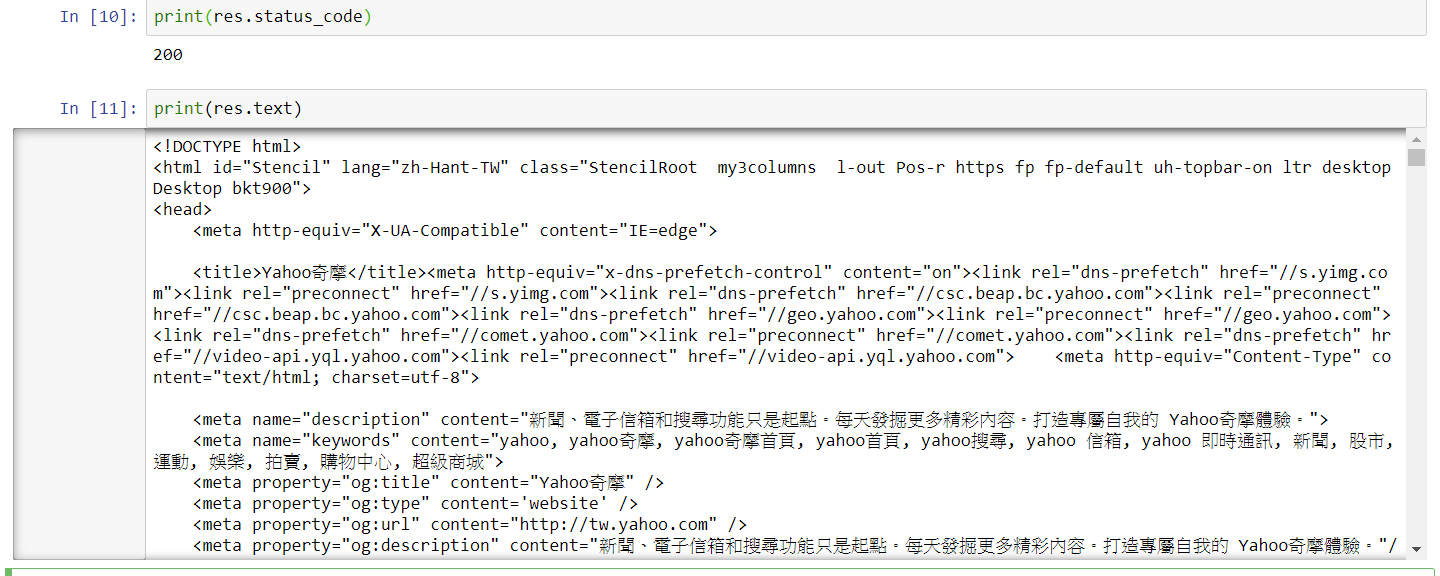
你也可以透過BeautifulSoup提取網頁原始碼再印出。
soup = BeautifulSoup(res.text)
print(soup)
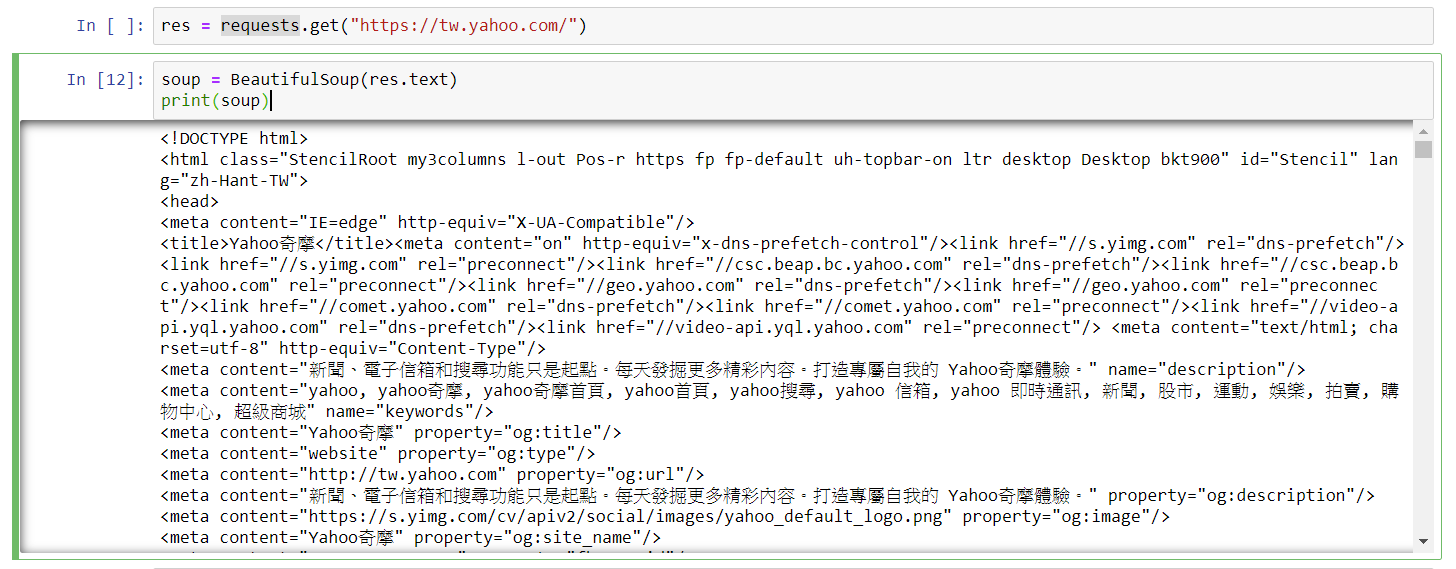
- 以 Beautiful Soup 解析 HTML 程式碼,並儲存在soup變數中。
#Python標準庫
soup = BeautifulSoup(res.text, 'html.parser')
- 我們可以利用
find_all找出所有特定的 HTML 標籤節點。
data = soup.find_all("標籤", "class")
回憶一下我們剛剛是不是在yahoo奇摩首頁找到了新聞的標籤及class?
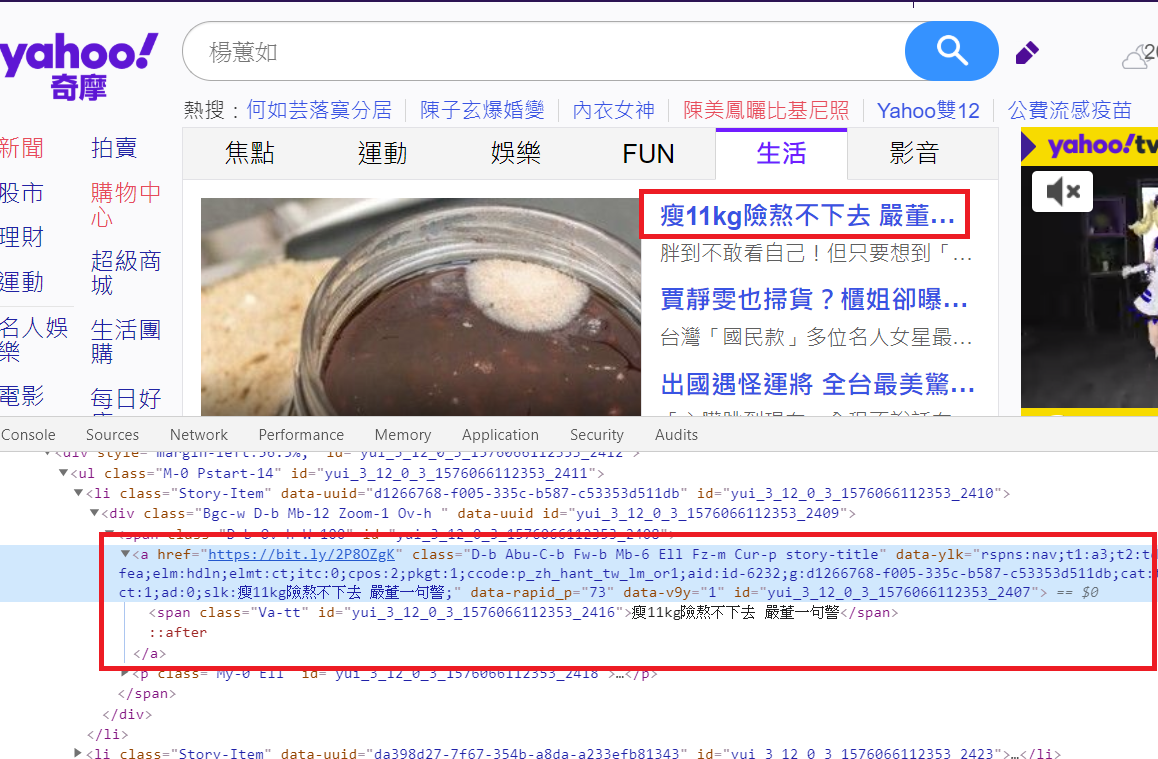
因此我們可以找到class為story-title的a標籤,並將之存在data變數當中。
data = soup.find_all("a", "story-title")

- 以 Python 的迴圈來依序輸出每個超連結的文字以及使用get來取得class為
story-title的a標籤中的href內容:
for s in data:
print("新聞標題:" + s.text)
print("新聞地址:" + s.get("href"))

至此,本節課的目標達成啦!但現在僅僅只是沾上爬蟲的邊,未來還有許多要學習呢!