初學者也能快速上手的Python爬蟲(4) - 發票兌獎

💜在開始之前推薦一個很棒的在線編輯網站,可寫python即時預覽repl.it
統一發票:http://invoice.etax.nat.gov.tw/
首先,我們需要安裝的套件有:
- BeautifulSoup
- urllib.request - 用於打開URL
- prettytable - 用於設計好看的表格
Beautifulsoup我記得之前有說過如何安裝了,其他其實也是相同的安裝方式。
下載套件:https://pypi.org/
程式碼
首先先引入需要使用到的套件
#import
from bs4 import BeautifulSoup
from urllib.request import urlopen
from prettytable import PrettyTable
接著使用urlopen()來抓該網站的數據,接著以Beautiful Soup解析 HTML 程式碼:
html = urlopen("http://invoice.etax.nat.gov.tw/").read().decode('utf-8')
soup = BeautifulSoup(html,'html.parser')
❗️注意:
在python 2.x的版本,是用urllib2,而在python 3.x的版本,改用urllib,兩者的功能其實很相似。
urllib可以存取網頁、下載資料、剖析資料、修改表頭(header)、執行GET與POST的請求…。
再來打開統一發票的網站,按下F12打開開發人員工具並按下Ctrl+Shift+C指向想抓取的資料位置,
比如說中獎號碼:

你可以發現中獎號碼的html大概都長這樣:
<span class="t18Red">59647042</span>
...
<span id="newFirstPrize" class="t18Red">01616970<br>69921388<br>53451508</span>
...
他們之間的共同處有:
- 都使用span標籤
- class都是t18Red
如果有點基礎,你大概就知道要怎麼抓數據了。
這邊我使用find_all抓取全部class為t18Red的span標籤
data = soup.find_all('span',class_='t18Red')
❗️注意:
由於 class 是 Python 程式語言的保留字,所以 Beautiful Soup 改以 class_ 這個名稱代表 HTML 節點的 class 屬性
以下為關於find_all()的用法,轉自BrownWong
find_all()
- 查找标签 soup.find_all('tag')
- 查找文本 soup.find_all(text='text')
- 根据id查找 soup.find_all(id='tag id')
- 使用正则 soup.find_all(text=re.compile('your re')), soup.find_all(id=re.compile('your re'))
- 指定属性查找标签 soup.find_all('tag', {'id': 'tag id', 'class': 'tag class'})
————————————————
版权声明:本文为CSDN博主「BrownWong」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_16912257/article/details/53336353
再來,可利用的資料還有
<h2>108年11-12月</h2>
<p class="date">領獎期間自109年02月06日起至109年05月05日止</p>
如果你仔細看,可以看見網頁中第一個使用h2標籤的並非這句,而是
<h2 id="tabTitle"><span>統一發票號碼獎中獎號碼</span> | <a href="/nowNumber.html">雲端發票專屬獎中獎號碼</a></h2>
因此,若要抓日期的話,要取h2標籤第一個資料,而不是第零個。
version = soup.find_all('h2')
print("當前期數:"+version[1].text+"\n")
再來領獎期限就更好抓了,不解釋
date = soup.find('p',class_='date')
print(date.text)
該抓的數據都抓好了,剩下就是美化跟排版
獎類方面我是直接手打儲存成list
A = ['特別獎','特獎','頭獎','增開六獎']
截至目前為止,我們的程式碼應該長這樣:
#import
from bs4 import BeautifulSoup
from urllib.request import urlopen
from prettytable import PrettyTable
html = urlopen("http://invoice.etax.nat.gov.tw/").read().decode('utf-8')
soup = BeautifulSoup(html,'html.parser')
data = soup.find_all('span',class_='t18Red')
version = soup.find_all('h2')
date = soup.find('p',class_='date')
A = ['特別獎','特獎','頭獎','增開六獎']
print("當前期數:"+version[1].text+"\n"+date.text+"\n")
再來,新增一個list B還有i = 0
i = 0
B = []
新增一個迴圈用來顯示中獎號碼
for number in data:
B = [number.text]
k = 0
while i<4 and k<1:
table = PrettyTable(['獎別','中獎號碼'])
table.add_row([A[i],B[k]])
#print(A[i])
#print(B[k])
i = i+1
k = k+1
print(table)
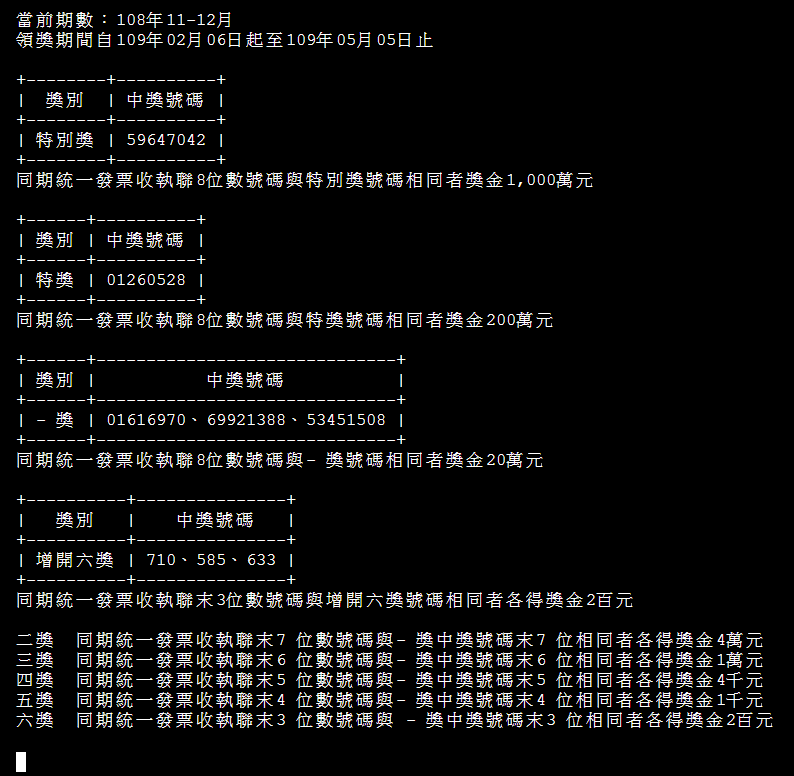
if i== 1 :
print("同期統一發票收執聯8位數號碼與特別獎號碼相同者獎金1,000萬元\n")
elif i== 2 :
print("同期統一發票收執聯8位數號碼與特獎號碼相同者獎金200萬元\n")
elif i== 3 :
print("同期統一發票收執聯8位數號碼與頭獎號碼相同者獎金20萬元\n")
elif i== 4 :
print("同期統一發票收執聯末3位數號碼與增開六獎號碼相同者各得獎金2百元\n")
最後在迴圈外面加上其他獎類的說明:
print("二獎 同期統一發票收執聯末7 位數號碼與頭獎中獎號碼末7 位相同者各得獎金4萬元\n三獎 同期統一發票收執聯末6 位數號碼與頭獎中獎號碼末6 位相同者各得獎金1萬元\n四獎 同期統一發票收執聯末5 位數號碼與頭獎中獎號碼末5 位相同者各得獎金4千元\n五獎 同期統一發票收執聯末4 位數號碼與頭獎中獎號碼末4 位相同者各得獎金1千元\n六獎 同期統一發票收執聯末3 位數號碼與 頭獎中獎號碼末3 位相同者各得獎金2百元")
如此一來,簡單的發票網頁爬蟲就已經結束,你還可以挖掘更多的玩法或者美化它,剩下的就交給你啦!
接著就是PrettyTable的一些補充,有興趣就繼續看吧。
Pretty Table
這之中我們用到了PrettyTable,這是一個python的第三方套件,主要功能是將文字內容以表格的方式整齊、簡潔的輸出成一個文字檔,並且可以自行控制表格框線、排序方式、對齊方式,另外Pretty Table也支援從現有的文件來產生表格(CSV、HTML、SQL)。
詳細的使用說明歡迎請教谷歌大師,
簡單的用法範例,下面為Row by Row
from prettytable import PrettyTable
x = PrettyTable()
x.field_names = ["City name", "Area", "Population", "Annual Rainfall"]
x.add_row(["Adelaide",1295, 1158259, 600.5])
x.add_row(["Brisbane",5905, 1857594, 1146.4])
x.add_row(["Darwin", 112, 120900, 1714.7])
x.add_row(["Hobart", 1357, 205556, 619.5])
x.add_row(["Sydney", 2058, 4336374, 1214.8])
x.add_row(["Melbourne", 1566, 3806092, 646.9])
x.add_row(["Perth", 5386, 1554769, 869.4])
Column by Column
from prettytable import PrettyTable
x = PrettyTable()
x.add_column("City name",
["Adelaide","Brisbane","Darwin","Hobart","Sydney","Melbourne","Perth"])
x.add_column("Area", [1295, 5905, 112, 1357, 2058, 1566, 5386])
x.add_column("Population", [1158259, 1857594, 120900, 205556, 4336374, 3806092,
1554769])
x.add_column("Annual Rainfall",[600.5, 1146.4, 1714.7, 619.5, 1214.8, 646.9,
869.4])
引入CSV檔案的數據
from prettytable import from_csv
fp = open("myfile.csv", "r")
mytable = from_csv(fp)
fp.close()
引入數據庫資料
import sqlite3
from prettytable import from_cursor
connection = sqlite3.connect("mydb.db")
cursor = connection.cursor()
cursor.execute("SELECT field1, field2, field3 FROM my_table")
mytable = from_cursor(cursor)
其他的官方說明文件都有:https://github.com/jazzband/prettytable